


TL;DR
Why Does Scalability Mean More Than Auto-Scaling in Real-Time Streaming Systems?
When engineers discuss scalability, the conversation often starts with compute.
Can the platform scale from 10,000 events per second to 100,000 events per second? Can additional instances be provisioned automatically? How quickly can workloads scale during traffic spikes?
While these are important considerations, compute provisioning is rarely the first bottleneck in production streaming systems. A real-time streaming pipeline consists of multiple layers, each introducing its own scalability constraints.
Streaming Scalability Layers
Layer | Primary Responsibility | Common Scalability Bottleneck |
Ingestion | Accept incoming events | Request concurrency, network throughput |
Transport | Move events between systems | Broker throughput, partition parallelism |
Processing | Execute business logic | Consumer lag, processing latency |
State Management | Maintain context across events | State-store growth, checkpoint recovery |
Operations | Manage and monitor the platform | Observability, deployment complexity, governance |
As event volumes increase, bottlenecks typically move across these layers rather than remaining fixed within a single component. Consider a streaming platform processing 100,000 events per second.
Adding additional compute capacity may increase available CPU resources, but it does not automatically improve:
Event transport throughput
Consumer processing efficiency
Stateful aggregation performance
Checkpoint recovery times
End-to-end pipeline latency
This is why many streaming systems continue to experience growing lag and latency despite having available compute resources.
Example: Why More Compute Does Not Always Increase Throughput
Consider a real-time order processing pipeline.
Order Events
Streaming Platform
Processing Layer
Analytics & Applications
Initially, the system processes:20,000 Events/Second
Traffic grows to: 100,000 Events/Second
The natural response is to add more compute.
However, if the processing layer cannot consume events fast enough, backlog begins accumulating.
Ingress Rate > Processing Rate = Consumer Lag
At this point, the scalability problem is no longer infrastructure provisioning. The problem has shifted to processing efficiency. Similarly, if processing requires maintaining large state stores for aggregations, joins, or AI feature generation, the bottleneck may shift again to state management rather than compute availability. Understanding where these constraints emerge is critical when evaluating serverless and containerized streaming architectures. The first layer where these differences become visible is event ingestion.
How Does Scalability Break Down Across the Different Layers of a Streaming System?
When discussing scalability, many engineering teams focus primarily on compute capacity.
Can additional instances be provisioned?
Can workloads scale horizontally?
Can infrastructure absorb traffic spikes?
While these are important considerations, real-time streaming systems scale across multiple independent layers, each introducing its own constraints. As event volumes grow, bottlenecks rarely remain isolated to a single component. Instead, they move between ingestion, transport, processing, state management, and operational layers depending on workload characteristics.
The Five Layers of Streaming Scalability
Layer | Responsibility | Typical Bottleneck |
Ingestion | Accept incoming events | Request concurrency, network throughput |
Transport | Move events between producers and consumers | Broker throughput, replication traffic, partition parallelism |
Processing | Execute business logic on events | Consumer lag, processing latency |
State Management | Maintain context across events | State-store growth, checkpoint recovery |
Operations | Deploy, monitor, and govern the platform | Observability gaps, deployment complexity, governance overhead |
Each layer introduces different scaling requirements. For example, a streaming platform may successfully ingest 100,000 events per second but still fail to process them in real time if downstream consumers cannot keep pace.
Similarly, a processing engine may have sufficient compute resources but experience increasing latency because state stores have grown beyond available memory or checkpoint durations have become excessively long.
Why Scalability Bottlenecks Shift Over Time
Most streaming platforms scale in stages.
> Initially, the challenge is handling incoming traffic.
10,000 Events/sec - Event Ingestion
> As traffic grows, transport throughput becomes the limiting factor.
100,000 Events/sec - Message Transport
> At larger scales, processing efficiency becomes the primary concern.
500,000 Events/sec - Consumer Processing
> Eventually, state management and operational complexity dominate.
1M+ Events/sec - State Stores, Checkpoints, Observability, Governance
This is why scaling a real-time data platform is fundamentally different from scaling a traditional web application. Adding more compute does not automatically improve
Event transport throughput
Consumer efficiency
State-store performance
Checkpoint recovery times
End-to-end latency
Understanding where these bottlenecks emerge is critical when evaluating serverless and containerized streaming architectures. The first layer where the architectural differences become visible is event ingestion.
How Does Event Ingestion Become the First Scalability Challenge in Streaming Architectures?
Every real-time streaming platform begins at the ingestion layer. Before events can be enriched, aggregated, correlated, or analyzed, they must first enter the system.
At small scale, ingestion appears straightforward. Applications produce events, APIs receive requests, and messages are forwarded to a transport layer. However, as event volumes increase, ingestion becomes the first layer exposed to traffic variability.
Unlike downstream processing systems that often operate at relatively stable rates, ingestion layers must absorb whatever traffic arrives, regardless of volume, timing, or distribution.
Why Is Event Ingestion Different From Other Streaming Layers?
Most streaming systems experience uneven traffic patterns. Common examples include:
Event Source | Traffic Pattern |
Mobile Applications | User-driven bursts |
IoT Devices | Reconnection storms |
Web Applications | Peak-hour traffic spikes |
AI Systems | Inference bursts |
Observability Pipelines | Incident-driven surges |
Business Applications | Batch-triggered event floods |
A platform may normally process: 10,000 Events/sec but suddenly experience: 250,000 Events/sec during a product launch, software deployment, regional outage, or device reconnect event.
The challenge is not average throughput. The challenge is absorbing unpredictable bursts without introducing event loss, excessive latency, or downstream bottlenecks.
What Happens When Ingestion Capacity Cannot Keep Pace?
When incoming traffic exceeds available ingestion capacity, several failure patterns emerge.
Failure Pattern 1: Request Backlogs
Ingress Rate > Accepted Rate = Queue Growth
Requests begin accumulating faster than they can be processed. Latency increases even before failures occur.
Failure Pattern 2: Connection Saturation
Available Connections < Incoming Requests
Applications begin experiencing throttling, connection resets, or timeout errors.
Failure Pattern 3: Cascading Pipeline Delays
> Ingestion Delay
> Transport Delay
> Processing Delay
> Business Impact
Even if downstream systems have available capacity, ingestion bottlenecks prevent events from entering the pipeline quickly enough.
Why Does Traditional Capacity Planning Struggle with Streaming Ingestion?
Historically, organizations addressed traffic growth through infrastructure provisioning.
> Expected Peak Traffic
> Provision Capacity
> Handle Requests
This approach works when workloads are predictable. Streaming systems are rarely predictable. Provisioning for average traffic introduces risk during spikes. Provisioning for worst-case traffic leads to excessive infrastructure costs.
Ingestion Scaling Trade-Offs
Strategy | Benefit | Drawback |
Scale for Average Traffic | Lower Cost | Risk of overload |
Scale for Peak Traffic | High Reliability | Significant overprovisioning |
Dynamic Scaling | Balanced Utilization | Requires automation |
As streaming platforms mature, dynamic scaling becomes increasingly important because traffic variability often grows faster than average throughput. This is where serverless architectures gained popularity. Instead of scaling infrastructure ahead of demand, serverless platforms scale execution resources in response to incoming events.
The question is whether this elasticity remains effective as event volumes continue to grow and processing requirements become more complex.
How Do Serverless Architectures Handle Burst Traffic and Elastic Scaling?
Serverless architectures were designed to solve one of the most difficult problems in distributed systems: unpredictable demand.
Instead of provisioning infrastructure in advance, serverless platforms allocate compute resources dynamically in response to incoming events.
Every event triggers an execution unit.
“Event- Function Execution”
As event volume increases, additional execution environments are automatically provisioned.
> 10 Events/sec - 10 Executions
> 1,000 Events/sec - 1,000 Executions
> 100,000 Events/sec - 100,000 Executions
From an ingestion perspective, this model is extremely powerful because scaling occurs at the request level rather than the infrastructure level.
Why Is Serverless Well Suited for Event Ingestion?
The ingestion layer has three primary requirements:
Requirement | Why It Matters |
Burst Absorption | Traffic is unpredictable |
Fast Scale-Out | Demand changes rapidly |
Cost Efficiency | Idle capacity should be minimized |
Serverless platforms address all three. Rather than maintaining idle infrastructure waiting for traffic spikes, resources are provisioned only when events arrive.
This makes serverless particularly effective for:
Webhook ingestion
Event routing
API event processing
Log ingestion
Data validation
Schema enforcement
Notification pipelines
How Does Request-Level Scaling Differ From Infrastructure Scaling?
Traditional infrastructure scales in units of servers, containers, or pods.
> Traffic Increase
> Add Servers
> Add Capacity
Serverless scales in units of executions.
> Traffic Increase
> New Invocation
> Additional Compute
This reduces operational overhead because engineering teams do not need to continuously adjust scaling policies for ingestion workloads.
Why Does Serverless Appear Infinitely Scalable?
From a developer’s perspective, serverless platforms often appear to provide unlimited scalability. However, every platform operates within practical limits.
Common Scaling Constraints
Constraint | Operational Impact |
Concurrent Executions | Request throttling |
Network Throughput | Increased latency |
Invocation Limits | Event backlog growth |
Execution Duration | Processing failures |
External Dependencies | Downstream bottlenecks |
These limitations are rarely visible at lower traffic volumes. As throughput increases, they become increasingly important.
What Happens at 100,000+ Events Per Second?
> At lower event rates, infrastructure provisioning is the primary challenge.
> At higher event rates, the bottleneck often shifts elsewhere.
> Consider a streaming pipeline receiving: 100,000 Events/sec
Even if the serverless platform successfully scales executions, downstream systems must still:
Accept the events
Transport the events
Process the events
Store processing state
Deliver outputs
The ingestion layer may scale successfully while the rest of the platform struggles to keep pace. This is why scaling event ingestion does not automatically translate into end-to-end streaming scalability. The next bottleneck often emerges in the transport layer, where events must be moved reliably between producers and consumers at scale.
Why Does Transport Throughput Become the Next Scalability Bottleneck?
Successfully ingesting events is only the first step in a streaming architecture.
Once an event enters the platform, it must be transported reliably between producers, processors, applications, storage systems, and downstream consumers.
At lower traffic volumes, transport is rarely a concern.
At scale, however, transport throughput often becomes the first major bottleneck after ingestion.
This is because transport systems must satisfy competing requirements simultaneously:
High throughput
Low latency
Durability
Ordering guarantees
Fault tolerance
Consumer scalability
Unlike request-response architectures where data is processed immediately, streaming systems continuously move data across distributed infrastructure.
Why Does Event Transport Become Difficult at Scale?
Consider a streaming platform processing: 100,000 Events/sec, Average Event Size: 5 KB
This produces: 500 MB/sec ≈ 43 TB/day
At this scale, transport is no longer a simple networking problem. The platform must continuously:
Accept incoming writes
Replicate data for durability
Serve multiple consumers
Maintain ordering guarantees
Recover from failures
Every one of these operations consumes resources.
Transport Scalability Constraints
Constraint | Impact |
Write Throughput | Producer latency increases |
Read Throughput | Consumer lag accumulates |
Replication Traffic | Network saturation |
Storage I/O | Increased commit latency |
Consumer Fan-Out | Resource contention |
Partition Distribution | Uneven workload allocation |
The challenge becomes particularly visible when multiple downstream systems consume the same event stream.
For example:
Applications
Kafka
|
+---- Analytics
|
+---- Data Lake
|
+---- AI Models
|
+---- Operational Systems
Every additional consumer increases transport demands. The system must not only ingest events but also distribute them efficiently across multiple workloads.
Why Doesn’t Additional Compute Solve Transport Bottlenecks?
A common misconception is that adding compute automatically improves throughput.
Consider the following scenario:
> Ingress Rate: 100,000 Events/sec
> Processing capacity is doubled.
> Consumers 2x Compute
However, throughput remains unchanged.
Why?
Because transport capacity is still constrained by:
Broker throughput
Storage performance
Network bandwidth
Parallelism limits
The bottleneck has simply moved. This is one of the fundamental differences between traditional application scaling and streaming platform scaling. In streaming systems, data movement often becomes the limiting factor long before compute resources are exhausted.
How Does Partition Parallelism Influence Streaming Scalability?
Most modern streaming platforms achieve scalability through partitioned data streams.
Partitions allow workloads to be distributed across multiple processing instances while maintaining ordered event sequences.
A simplified example:
Topic
|
+-- Partition 1
|
+-- Partition 2
|
+-- Partition 3
|
+-- Partition 4
Consumers can process partitions independently.
Partition 1 → Consumer A
Partition 2 → Consumer B
Partition 3 → Consumer C
Partition 4 → Consumer D
This creates horizontal scalability. However, partitions also introduce limits.
> If a topic contains: 12 Partitions
> then the maximum effective parallelism for a consumer group is: 12 Active Consumers
> Adding a 13th consumer provides no additional throughput.
This creates a hard scalability ceiling that cannot be solved through infrastructure provisioning alone.
Why Does Transport Scalability Eventually Become a Consumer Scalability Problem?
As throughput grows, transport bottlenecks begin appearing downstream. Events arrive successfully. Transport remains healthy. Yet consumers begin falling behind. This creates a new challenge:
Ingress Rate > Processing Rate = Consumer Lag
Consumer lag is one of the most important indicators of streaming platform health because it represents the difference between data entering the platform and data being processed.
At this stage, the bottleneck has shifted again. The challenge is no longer ingesting events. The challenge is processing them fast enough. This is where the limitations of serverless architectures begin to emerge and where containerized streaming architectures become increasingly important.
How Does Consumer Lag Become the Real Measure of Streaming Scalability?
One of the most common mistakes in streaming architecture is measuring scalability using infrastructure metrics alone.
Engineering teams often monitor:
CPU utilization
Memory consumption
Network throughput
Instance count
Container replicas
While these metrics indicate infrastructure health, they do not answer the most important question:
Is the platform processing data as fast as it is being generated?
This is where consumer lag becomes critical.
Consumer lag represents the difference between the latest event available in a stream and the latest event successfully processed by a consumer.
A simplified representation:
Latest Offset: 10,000,000
Processed Offset: 9,950,000
Consumer Lag: 50,000
As lag increases, data becomes progressively older before it reaches downstream systems.
Why Is Consumer Lag More Important Than CPU Utilization?
Consider two streaming applications.
Application A
CPU Usage: 90%
Consumer Lag: 0
Application B
CPU Usage: 25%
Consumer Lag: 500,000
Which application is healthier? Most monitoring systems would flag Application A. In reality, Application B is in far greater danger. Application A is fully utilizing available resources while keeping pace with incoming traffic. Application B appears healthy from an infrastructure perspective but is silently falling behind.
This is why consumer lag is often the most important scalability metric in streaming systems.
What Causes Consumer Lag?
Consumer lag emerges whenever: Ingress Rate > Processing Rate
This imbalance can occur for several reasons.
Processing Bottlenecks
Business logic becomes increasingly expensive.Examples include:
Data enrichment
External API calls
AI inference
Schema validation
Event correlation
Complex transformations
Each additional operation increases processing time.
Resource Bottlenecks
Consumers may be constrained by:
CPU saturation
Memory pressure
Storage I/O
Network latency
In these scenarios, events continue arriving faster than they can be processed.
Parallelism Bottlenecks
Consumer scalability is bounded by partition availability.
For example, 24 Partitions for Maximum effective parallelism: 24 Active Consumers. Adding more consumers beyond available partitions does not increase throughput.
Why Does Lag Matter in Real-Time Systems?
Lag is not merely a performance metric. It directly affects business outcomes.
Example: Fraud Detection
Fraud signals arrive in real time.
Transaction
Fraud Detection
Decision
If lag reaches: 5 Minutes
the fraud engine is effectively operating on historical data. The system remains technically functional but no longer behaves as a real-time platform.
Example: Operational Intelligence
A manufacturing system monitoring equipment health may process: 50,000 Sensor Events/sec
Lag accumulation delays anomaly detection. The cost of delayed action may be significantly greater than infrastructure costs.
Why Does Backpressure Eventually Appear?
Lag rarely remains isolated. As consumers fall behind, queues begin growing throughout the pipeline.
> Producer
> Transport Layer
> Consumer Lag
> Queue Growth
> Increased Latency
This phenomenon is known as backpressure.
Backpressure occurs when downstream systems cannot process events at the rate they are received.
The effect propagates upstream through the architecture.
Without mitigation, this creates:
Increased latency
Resource exhaustion
Growing storage requirements
Processing instability
At this stage, scaling compute alone often provides diminishing returns.
The bottleneck shifts from ingestion and transport to processing efficiency itself. This is the point where architectural differences between serverless and containerized streaming become most apparent.
Why Do Stateful Streaming Workloads Become the Breaking Point for Serverless Architectures?
Serverless architectures excel at processing independent events. Each invocation receives an event, executes business logic, returns a result, and terminates.
> Event
> Function
> Output
This execution model works exceptionally well for stateless workloads such as:
Event validation
Schema enforcement
Data routing
Webhook processing
Notification delivery
Lightweight transformations
However, most production streaming systems are not stateless. As streaming platforms mature, processing requirements become increasingly dependent on historical context.
What Makes a Streaming Workload Stateful?
A workload becomes stateful when processing an event requires information from previous events. Examples include:
Sessionization
User Event 1 + User Event 2 + User Event 3 = Single User Session
Windowed Aggregations
Count all transactions during the last 15 minutes
Event Correlation
Login Event + Payment Event + Location Event = Fraud Signal
Real-Time Analytics
Millions of Events - Running Aggregates
In all these scenarios, processing an event requires access to previously processed data.
Why Is State Difficult in Serverless Architectures?
The fundamental challenge is that serverless functions are ephemeral. Each execution is designed to be independent. A function cannot assume:
Previous executions still exist
Local memory is available
State remains cached
Processing context persists
As a result, state must be externalized.
Typical architecture:
Event
Function
|
+---- State Store
|
+---- Cache
|
+---- Database
Every state lookup introduces additional:
Network latency
Storage overhead
Failure points
Cost
The more state a workload requires, the more frequently the function must leave its execution environment to retrieve context.
What Happens When State Continuously Grows?
Consider a real-time recommendation engine. 10 Million Users Each user generates: 50 Events/Day
Total: 500 Million Events/Day
Now imagine maintaining:
User behavior history
Session state
Product interactions
Recommendation scores
The challenge is no longer event processing. The challenge becomes managing continuously growing state.
Why Do Windowed Aggregations Expose Serverless Limitations?
Many streaming systems rely on time-based windows.
Examples include:
Last 5 Minutes
Last 15 Minutes
Last 1 Hour
Last 24 Hours
For every incoming event, the system must:
Retrieve current window state
Update aggregations
Persist new state
Maintain recovery information
The larger the window, the larger the state footprint.At scale, this creates substantial storage and retrieval overhead.
Why Does Exactly-Once Processing Become More Complex?
Modern streaming systems often require: Process Event Once, Only Once Not Zero Times or Multiple Times
Achieving exactly-once semantics requires:
Offset tracking
State synchronization
Checkpoint coordination
Recovery mechanisms
These requirements become increasingly difficult when compute instances are short-lived and stateless by design.
Why Do Long-Running Streaming Applications Favor Persistent Execution Environments?
As state grows, the ideal architecture changes. Instead of repeatedly retrieving state:
> Event
> Function
> External State
The system benefits from keeping state close to processing.
Event
Processor
+---- Local State
This reduces:
Network calls
Storage lookups
Processing latency
Operational overhead
The ability to maintain state locally becomes increasingly important as event volumes, processing complexity, and throughput requirements grow. This is where containerized streaming architectures gain a significant advantage over purely serverless execution models.
How Do Containerized Streaming Architectures Manage State, Throughput, and Recovery More Efficiently?
The primary advantage of containerized streaming architectures is not compute control.
It is execution continuity.
Unlike serverless environments, where processing is distributed across short-lived execution contexts, containerized streaming applications operate as persistent processing engines.
Event Stream
Long-Running Processor
|
+---- Local State
|
+---- Checkpoints
|
+---- Persistent Storage
This architecture fundamentally changes how streaming systems manage throughput, state, and failure recovery.
Why Does Persistent Execution Matter for Streaming Workloads?
Most real-time streaming applications process far more than individual events.
They continuously maintain:
Session state
Running aggregates
Event correlations
Feature stores
Machine state
User behavior history
These workloads benefit from keeping state close to the processing engine.
Instead of retrieving context for every event:
> Event
> External State Lookup
> Process Event
state remains available locally.
> Event
> Local State
> Process Event
This significantly reduces processing latency and network overhead.
How Does Local State Improve Processing Throughput?
Consider a stream processor handling: 200,000 Events/sec
If every event requires: 5 ms of additional network latency to retrieve state, the cumulative impact becomes substantial. The system spends more time waiting for state retrieval than performing business logic.
By maintaining local state stores, processing becomes:
> Event
> Memory / Local Disk
> Process
Instead of:
> Event
> Remote Database
> Process
At scale, this difference directly affects throughput, latency, and infrastructure cost.
Why Is Checkpointing Critical for Stateful Stream Processing?
State introduces a new challenge:
What Happens If The Processor Fails?
Without recovery mechanisms, all accumulated state is lost. Containerized streaming architectures solve this through checkpointing.
A checkpoint captures:
Processing offsets
Application state
Aggregation results
Recovery metadata
Example:
Event Stream
Processor
|
+---- Checkpoint 1
|
+---- Checkpoint 2
|
+---- Checkpoint 3
If a failure occurs, processing resumes from the latest valid checkpoint rather than restarting from the beginning.
Why Does Checkpoint Recovery Time Influence Scalability?
Many teams focus on throughput.Experienced platform engineers focus on recovery.
A streaming application processing: 1 Million Events/sec, may perform perfectly under normal conditions.
The real test occurs during:
Node failures
Process crashes
Infrastructure upgrades
Scaling events
Recovery speed determines how quickly the platform returns to normal operation.
Recovery Characteristics
Recovery Scenario | Operational Impact |
Fast Checkpoint Recovery | Minimal disruption |
Slow Checkpoint Recovery | Growing lag |
Full State Rebuild | Significant downtime |
No Recovery Strategy | Data loss risk |
For large-scale streaming systems, recovery behavior often matters more than peak throughput benchmarks.
How Does Stateful Processing Affect Horizontal Scalability?
Scaling stateless workloads is straightforward.
> 1 Instance
> 10 Instances
> 10x Capacity
Stateful workloads introduce additional complexity. State must remain:
Consistent
Durable
Recoverable
Every scaling event potentially requires:
State movement
Partition reassignment
Checkpoint synchronization
Recovery operations
This is one of the reasons streaming platforms require more sophisticated scaling strategies than traditional web applications.
Why Do Long-Running Stream Processors Deliver More Predictable Latency?
Serverless systems optimize for elasticity. Containerized systems optimize for consistency. Because stream processors remain active:
State stays warm
Connections remain established
Caches remain populated
Processing pipelines remain initialized
This eliminates many of the latency spikes associated with repeatedly initializing execution environments.
For workloads involving:
Real-time analytics
Event correlation
AI feature generation
Stateful aggregations
Continuous monitoring
predictable latency is often more valuable than instantaneous scaling.
Containerized Streaming Strengths
Capability | Operational Benefit |
Long-Running Execution | Stable processing environment |
Local State Stores | Lower latency |
Checkpointing | Faster recovery |
Persistent Storage | Durable state management |
Resource Control | Predictable performance |
Stateful Processing | Native support |
Throughput Optimization | Efficient event processing |
This is why most high-throughput streaming platforms rely on containerized processing for the core execution layer.
The challenge, however, is that containerized architectures introduce their own operational complexity. While they solve state management and throughput problems, they require careful capacity planning, orchestration, deployment management, and scaling strategies.
This raises the next question: If serverless excels at ingestion and containers excel at processing, why do most production streaming platforms ultimately combine both architectures?
Why Do Most Production Streaming Platforms Adopt Hybrid Architectures?
Serverless architectures excel at handling unpredictable event ingress, while containerized architectures excel at sustained, stateful stream processing. The reality is that most large-scale streaming systems require both capabilities simultaneously.
Consider a real-time data platform processing:
Customer activity streams
IoT telemetry
Application events
Transaction data
Operational metrics
AI inference requests
These workloads rarely exhibit uniform behavior across the entire pipeline. The ingestion layer may experience highly variable traffic patterns, while downstream processing workloads operate continuously. As a result, different layers of the platform benefit from different execution models.
The Evolution of Streaming Architectures
Many streaming systems evolve through three stages.
Stage 1: Centralized Processing
> Events
> Processing Layer
> Applications
At low scale, this architecture is simple and effective. However, as event volumes increase, a single processing layer becomes increasingly difficult to scale.
Stage 2: Elastic Ingestion
> Events
> Serverless Ingestion
> Processing Layer
Serverless execution helps absorb traffic spikes without requiring constant infrastructure provisioning. This significantly improves ingestion scalability. However, downstream processing systems eventually become the next bottleneck.
Stage 3: Distributed Streaming Platform
> Events
> Elastic Ingestion
> Streaming Platform
> Containerized Processing
> Applications
This architecture separates ingestion scalability from processing scalability. Each layer can now scale independently.
Why Does Independent Scaling Matter?
Different workloads grow at different rates. For example:
Layer | Growth Pattern |
Event Ingestion | Highly Variable |
Transport Throughput | Relatively Stable |
Stream Processing | Consistently Increasing |
State Management | Continuously Growing |
Analytics Consumption | Bursty |
Attempting to scale all layers together often leads to over-provisioning and unnecessary infrastructure costs. Independent scaling allows resources to be allocated where they are actually needed.
What Does a Modern Hybrid Streaming Architecture Look Like?
A typical architecture resembles:
Applications
Devices
APIs
Elastic Ingestion Layer
Streaming Platform
|
+---- Stream Processing
|
+---- Analytics
|
+---- AI Workloads
|
+---- Operational Systems
Each layer serves a specific purpose.
Hybrid Architecture Responsibilities
Layer | Primary Responsibility |
Elastic Ingestion | Burst absorption |
Streaming Platform | Event transport |
Stream Processing | Stateful computation |
Analytics | Insights generation |
Operational Systems | Business execution |
This separation improves:
Scalability
Reliability
Fault isolation
Resource utilization
Deployment flexibility
Why Is Kafka Commonly Used as the Decoupling Layer?
As architectures become distributed, components must scale independently.
Without a streaming platform:
Producer
Consumer
Every scaling decision affects both systems.
With a streaming platform:
Producer
Kafka
Consumers
Producers and consumers can evolve independently. This decoupling becomes increasingly valuable as event volumes and application complexity grow.
Why Doesn't Hybrid Architecture Eliminate Complexity?
Hybrid architectures solve many scalability challenges. However, they introduce a new category of problems. Engineering teams must now operate:
Kafka infrastructure
Stream-processing workloads
Connectors
Observability systems
Governance policies
Deployment workflows
Multi-environment configurations
As event volumes increase, operational complexity often grows faster than infrastructure itself. The challenge is no longer: How Do We Scale?
The challenge becomes: How Do We Operate A Platform That Scales? This is where operational scalability becomes the next architectural bottleneck.
How Does Operational Complexity Become the Final Scalability Bottleneck?
At smaller scales, scalability is primarily a technical problem. Engineering teams focus on:
Processing throughput
Infrastructure provisioning
Resource utilization
Application performance
As streaming systems mature, however, the bottleneck often shifts away from infrastructure and toward operations. This transition typically occurs when organizations move from managing a few streaming workloads to operating an entire streaming platform.
At this stage, the challenge is no longer: Can the System Scale?
The challenge becomes: Can Team Operate, The System at Scale?
Why Does Operational Complexity Grow Faster Than Event Volume?
Infrastructure scales linearly. Operations rarely do.
A platform processing: 10,000 Events/sec might require:
One cluster
A handful of connectors
Limited observability
Basic monitoring
The same platform processing: 1,000,000 Events/sec may require:
Multiple environments
Hundreds of pipelines
Dozens of connectors
Cross-team governance
Compliance controls
Advanced observability
Deployment automation
The growth in operational responsibility often exceeds the growth in infrastructure itself.
What Operational Challenges Emerge as Streaming Platforms Scale?
Infrastructure Management
Streaming platforms consist of multiple distributed components.
Examples include:
Kafka Clusters
Processing Applications
Connectors
Storage Systems
Monitoring Infrastructure
Each component introduces its own operational lifecycle. Engineering teams must continuously manage:
Capacity
Upgrades
Failures
Configuration changes
Security controls
Pipeline Sprawl
Most teams start with a few event pipelines. Over time:
10 Pipelines to 100 Pipelines to 500 Pipelines
Visibility becomes increasingly difficult. Questions become harder to answer:
Which pipeline is failing?
Which transformation introduced latency?
Which deployment caused lag?
Which application owns the pipeline?
Observability Challenges
Monitoring individual components is relatively easy. Monitoring an entire streaming platform is not. A single event may traverse:
Producer
Connector
Streaming Platform
Transformation
Storage
Analytics
Identifying bottlenecks across these layers requires unified observability rather than isolated monitoring tools.
Governance Challenges
As event streams become business critical, governance requirements increase. Organizations must manage:
Access controls
Data ownership
Auditability
Compliance requirements
Schema governance
Environment isolation
Without centralized governance, platform growth introduces operational risk.
Why Does Platform Management Become a Scaling Problem?
Every new workload introduces additional operational overhead.
Consider: New Application
This often requires:
New Connector
New Processing Logic
New Monitoring
New Security Policies
New Deployment Workflows
As adoption increases, platform teams spend more time managing infrastructure than delivering new capabilities. At this point, operational scalability becomes just as important as infrastructure scalability.
Operational Scalability Challenges
Area | Technical Problem | Operational Problem |
Ingestion | Handling spikes | Managing connectors |
Transport | Throughput scaling | Managing clusters |
Processing | Consumer lag | Managing deployments |
State | Recovery and checkpoints | Managing lifecycle |
Observability | Collecting metrics | Correlating insights |
Governance | Access enforcement | Policy management |
The architecture may scale successfully. The platform team may not.
This is why many organizations eventually adopt streaming platforms rather than assembling and operating every component independently. The goal is not simply to scale infrastructure. The goal is to scale infrastructure, workloads, governance, observability, and developer productivity simultaneously. This is where full-stack streaming platforms become increasingly important.
How Does Condense Simplify Scalability Across Modern Streaming Architectures?
By the time organizations reach production scale, the debate between serverless and containerized streaming often becomes secondary. Most engineering teams discover that scaling infrastructure is only one part of the problem. The larger challenge is operating the complete streaming platform.
A production-grade real-time data system typically requires multiple layers working together:
Data Sources
Ingestion Layer
Streaming Infrastructure
Processing Logic
Observability
Governance
Applications & AI Systems
Each layer introduces additional operational responsibility. Teams must provision infrastructure, deploy processing logic, monitor system health, manage connectors, govern data movement, and continuously optimize performance as workloads evolve. This operational burden often grows faster than event volume itself.
Why Does Building a Streaming Platform Require More Than Kafka?
Many organizations initially approach real-time streaming as an infrastructure problem. The assumption is: Deploy Kafka = Real-Time Platform
In practice, Kafka is only one layer of a much larger architecture.
Engineering teams still need to build and operate:
Stream processing services
Custom transformations
Connectors
Observability systems
Governance controls
Deployment pipelines
Application runtimes
Scaling policies
As adoption grows, the challenge shifts from moving data to building applications on top of that data.
What Is Condense?
Condense by Zeliot is an AI-enabled full-stack data streaming platform built on Apache Kafka that unifies the infrastructure, processing, development, and operational layers required to build real-time applications. Rather than treating Kafka as a standalone messaging system, Condense provides a complete application platform for developing, deploying, operating, and scaling real-time workloads.
Condense Architecture
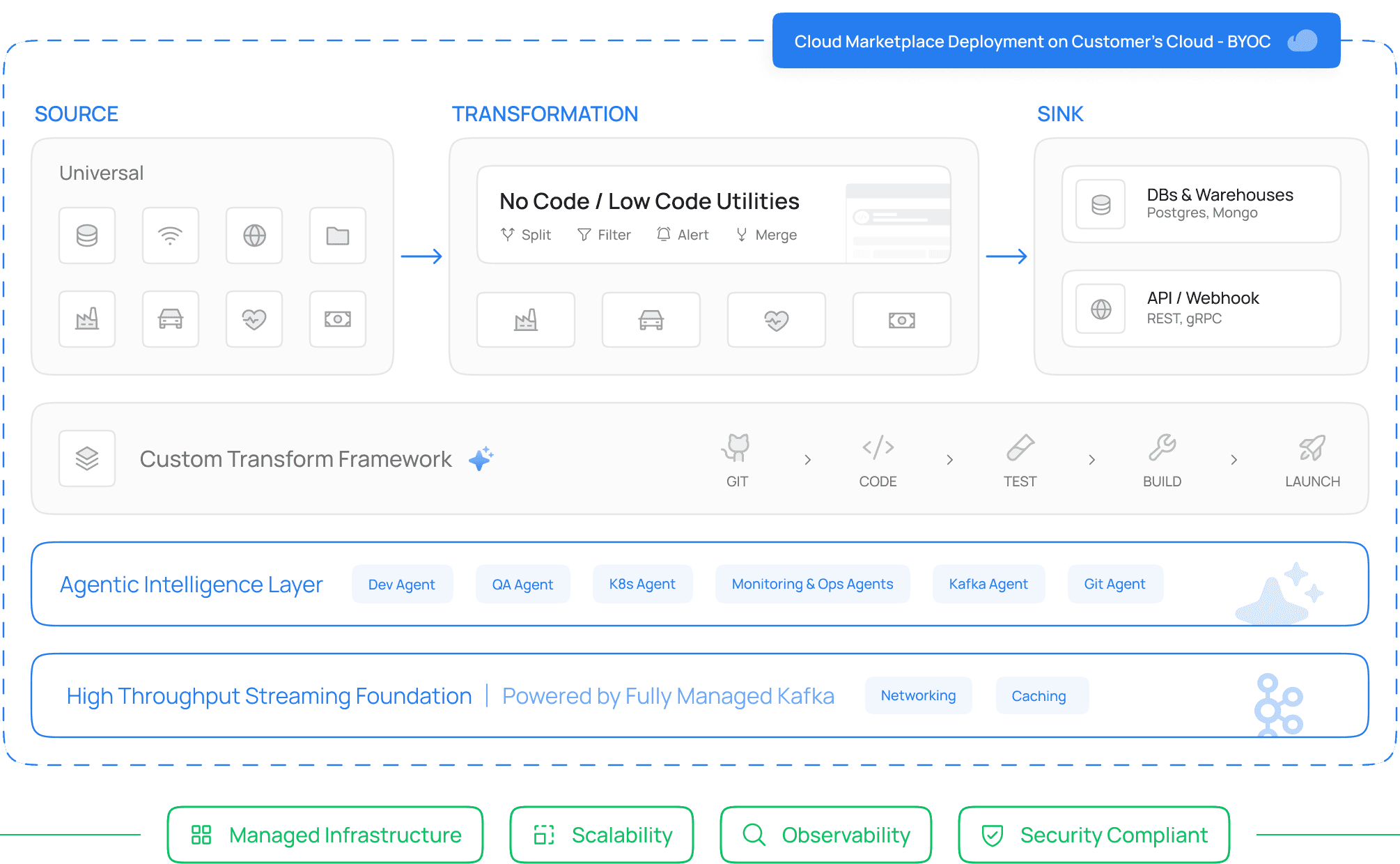
Unlike traditional streaming stacks where engineering teams assemble multiple technologies independently, Condense provides a unified execution environment that combines streaming infrastructure, application runtime, observability, and operational automation into a single platform.
How Does Condense Address Each Scalability Layer?
Scalability Layer | Common Challenge | Condense Approach |
Ingestion | Connecting diverse data sources | Prebuilt and industry-specific connectors |
Transport | Managing Kafka infrastructure | Fully managed Kafka with BYOC deployment |
Processing | Building stream-processing applications | Custom Transformation Framework and event-driven runtime |
State Management | Maintaining reliable execution | Managed deployment and runtime orchestration |
Observability | Monitoring distributed workloads | Built-in observability and AI-assisted insights |
Operations | Managing platform complexity | Unified platform with automated operations |
How Does Condense Reduce Operational Overhead?
A traditional streaming implementation often requires teams to manage multiple independent systems.
Kafka + Kubernetes + Monitoring + Connectors + Custom Runtime + Deployment Pipelines
Every component introduces additional deployment, maintenance, and operational overhead. Condense collapses these layers into a single operational platform. Engineering teams can build custom stream-processing logic, deploy real-time applications, manage connectors, monitor workloads, and operate streaming infrastructure through a unified experience.
How Does Condense Support Both Serverless and Containerized Architectural Patterns?
Modern streaming systems rarely rely on a single execution model. Some workloads require burst-driven elasticity. Others require long-running stateful processing.
Condense is designed around the streaming platform itself rather than a specific compute abstraction. This allows teams to build architectures that combine elastic event ingestion with stateful stream processing while operating both through a common platform layer.
As a result, engineering teams spend less time managing infrastructure boundaries and more time delivering real-time applications and data products. The result is a shift in focus from infrastructure operations to application outcomes. Instead of spending engineering effort managing Kafka clusters, deployment pipelines, observability stacks, and scaling policies, teams can concentrate on building the real-time capabilities that generate business value.
What Decision Framework Should Engineering Teams Use When Choosing Between Serverless and Containerized Streaming?
There is no universally correct answer to the serverless versus containerized streaming debate. The right architecture depends on which scalability constraint dominates the workload. Organizations often make the mistake of selecting an execution model first and attempting to fit every workload into it.
Successful streaming platforms work in the opposite direction. They identify bottlenecks first and then choose the execution model that best addresses them.
Decision Point 1: Is the Workload Primarily Ingestion or Processing Focused?
The first question should be: Where Is the Work being performed? If the primary responsibility is:
Event collection
API ingestion
Webhook processing
Event routing
Lightweight validation
then serverless architectures often provide the best operational and economic model. If the workload involves:
Stateful processing
Event correlation
Sessionization
Real-time analytics
AI feature generation
Long-running transformations
containerized execution becomes more appropriate.
Decision Matrix
Workload Characteristic | Serverless | Containers |
Event Ingestion | ✓ |
|
Burst Handling | ✓ |
|
Request-Level Scaling | ✓ |
|
Stateless Processing | ✓ |
|
Long-Running Services | ✓ | |
Stateful Processing | ✓ | |
Event Correlation | ✓ | |
Windowed Aggregations | ✓ | |
Predictable Latency | ✓ | |
Sustained Throughput |
| ✓ |
Decision Point 2: What Is the Traffic Pattern?
Traffic behavior is often more important than average throughput.
Bursty Traffic
10,000 Events/sec
150,000 Events/sec
10,000 Events/sec
Examples:
Retail promotions
Mobile notifications
Incident alerts
Customer activity spikes
Serverless architectures are typically well suited to these scenarios because infrastructure scales only when required.
Continuous Traffic
100,000 Events/sec
Examples:
IoT telemetry
Vehicle tracking
Manufacturing systems
Operational monitoring
Containerized processing generally provides better cost efficiency and performance predictability for sustained workloads.
Decision Point 3: How Important Is State?
State is often the deciding factor. Ask, does Processing an Event require knowledge of previous Events? If the answer is no:
Event
Process
Output
Then serverless architectures remain highly effective.
If the answer is yes, Historical Context + Current Event = Result
containers generally provide a more efficient execution model.
Decision Point 4: Is Operational Simplicity More Important Than Infrastructure Control?
Some organizations prioritize:
Rapid delivery
Reduced operational burden
Faster experimentation
Others require:
Resource tuning
Performance optimization
Infrastructure customization
Specialized runtime environments
This often influences architecture decisions as much as technical requirements.
Why Do Most Production Platforms Ultimately Choose Hybrid Architectures?
The reality is that modern streaming platforms rarely fit entirely into one category. Different workloads within the same platform frequently have different requirements.
For example:
Elastic Event Ingestion
Streaming Platform
Stateful Stream Processing
Analytics & AI Systems
In this architecture:
Serverless handles ingress variability
Streaming infrastructure provides decoupling
Containerized processors handle stateful computation
Each layer is optimized independently.
Recommended Architecture by Use Case
Use Case | Recommended Approach |
API Event Processing | Serverless |
Webhook Processing | Serverless |
Event Validation | Serverless |
Log Ingestion | Serverless |
Stream Aggregation | Containers |
Event Correlation | Containers |
AI Feature Engineering | Containers |
Real-Time Analytics | Containers |
Enterprise Streaming Platforms | Hybrid |
Large-Scale Data Streaming Platforms | Hybrid |
For most organizations, the question is not whether serverless or containers are better. The question is where each architecture delivers the greatest value within the streaming platform. The most successful real-time data platforms treat serverless and containerized execution as complementary capabilities rather than competing technologies.
Serverless architectures are ideal for elastic event ingestion and burst handling, while containerized architectures provide the consistency, state management, and sustained throughput required for core stream processing. Together, they form the foundation of most production-scale streaming systems.
The greater challenge, however, is not choosing an execution model; it is operating the platform that powers it. As streaming environments grow, teams must manage infrastructure, processing logic, observability, governance, connectors, and deployment of workflows across increasingly complex architectures.
Condense addresses this challenge with an AI-enabled full-stack data streaming platform by unifying managed Kafka, stream processing, AI-powered development, connectors, observability, governance, and operational automation, Condense enables engineering teams to build, deploy, and scale real-time applications without managing the underlying complexity of distributed streaming systems.



